

Editor’s Note: This blog post originally appeared on Josh Bickett’s Blog. It has been lightly edited and updated to reflect OpenAI’s announcement of Operator, an agent that "can use its own browser to perform tasks for you."
The Background
The first time I saw a computer-use AI agent was Sharif's GPT-3 demo in mid-2021. I was blown away. It autonomously browsed the web, clicked buttons to navigate, and purchased Airpods.
Over a year later in September 2022, a similar web-browsing agent project called Natbot was open-sourced and I got the chance to clone and try it. Nat completed the project in a weekend. He's a serious hacker.
After Natbot, our team at HyperWrite started building a web-browsing agent and after a few months of our heads down we launched what I understand to be the first commercially available web-browsing agent
A New Type of AI agent
While building a web-browsing agent, we came to understand the limitations of LLM-based web-browsing agents. LLMs can't see the visual representation of a page; they only process the HTML. Understanding a page purely through HTML context is challenging for LLMs. We anticipated multimodal agents that could interact with computers in a more human-like way would help address some of these challenges.
Prior to GPT-4-vision-preview, Matt Shumer had shared an idea about overlaying a grid on a screenshot and sending that to a multimodal model so it could estimate pixels to click on a screen.
LLaVA-1.5 was released in October 2023. Matt hosted the model and shared an endpoint with me. I started hacking around with it. We knew that GPT-4-vision-preview would arrive in the near future.
At first I called the project the Generalist Computer Agent. It would eventually become the Self-Operating Computer Framework.
I played with the idea of a visual OS-level agent for a week. One thing became clear: if you give a multimodal model an objective, pass it screenshots, and prompt it to output mouse and keyboard actions, it could operate a computer. I formulated an architecture and built out the framework. As far as I'm aware, this was the first such project with these capabilities.
The Architecture: Making AI Think and Act Like a Human
At its core, the self-operating framework operates through an elegant four-step loop that mirrors human decision-making:
- Observe: The AI receives three key inputs:
- The user's objective (what needs to be accomplished)
- A screenshot of the current screen (what the AI can "see")
- A prompt that guides its behavior (see below)
- Evaluate: The AI checks if the objective has been achieved
- Act: If the goal has not been met, the AI chooses one of four actions:
- Click: Moving the mouse to interact with elements
- Write: Typing text using the keyboard
- Press: Using keyboard shortcuts or special keys
- Done: Signaling task completion
- Repeat: This cycle continues until the objective is achieved
This simple yet powerful loop allows the AI to navigate computers just as a human would, making decisions based on what it sees on screen and taking appropriate actions to achieve its goals.
Self-Operating Computer System Prompt
You are operating a computer, using the same operating system as a human. From looking at the screen, the objective, and your previous actions, take the next best series of action. You have 4 possible operation actions available to you. Thepyautoguilibrary will be used to execute your decision. Your output will be used in a json.loads statement.
1.click - Move mouse and click - Look for text to click. Try to find relevant text to click, but if there's nothing relevant enough you can return "nothing to click" for the text value and we'll try a different method.
2. write - Write with your keyboard
3. press - Use a hotkey or press key to operate the computer
4. done - The objective is completed
After tinkering and iterating I could not get this working reliably with Llava-1.5. Then, on November 6, gpt-4-vision-preview was released. I hooked up gpt-4-vision-preview and I gave it the objective: "write a poem in the new note window."
I took my hands off the keyboard and saw the model output a mouse pixel. Pyautogui read the pixel location. The mouse moved over the new note pad. The model output a click event. Pyautogui fired the click event. The model output a poem. Pyautogui typed the poem.
It happened all on its own, and I was left staring at the completed poem in the Note. I realized that may have been the first time a VLM (vision language model) operated a computer. It was a surreal moment.
Self-Operating Computer Operating System Commands
Keyboard | pyautogui.write
This operation is straightforward. The LLM completion is simply passed to the pyautogui function.
Mouse Click | pyautogui.moveTo & pyautogui.click
This is a bit trickier, I had to figure out how to get the mouse to click on the right spot. I ended up using a grid system and sending the grid to the model. The model would guess the width and height in % of the total and I'd convert it to pixels.
Open-Sourcing the Self-Operating Computer Framework
I was eager to share the results. I posted on Twitter and the community's reaction was greater than I imagined.
A demo wasn't enough, and I wanted to get an open-source project into the community's hands so they could try it themselves. It also still had some issues to be worked out. I sorted through the most common use cases in my head and ran them to identify bugs. Then I fixed those bugs. I iterated on this for a while until I felt that the project was good enough to wow people when they tried it the first time. Twenty days later, I launched it to the open-source community and the post went viral. Shortly after it became the #1 trending project on GitHub.
Post-Launch and Beyond
For the first time, I was learning how to manage an open-source project that developers wanted to contribute to. That was a fun and interesting challenge. Over the first few weeks I reviewed new PRs the first day they were put up. Anyone who submitted a strong PR was added to an email group. These contributors were a great help and I was able to send issues into this group and often someone would pick up the issue and go fix it. @michaelhhogue provided high-quality PRs and was very responsive so I added him as a maintainer. In retrospect, one of my favorite parts was witnessing an open-source community develop firsthand and meeting collaborators who just show up and push valuable code.
The next project I saw use a vision model to operate the computer was Open Interpreter 0.2.0. A few things impressed me by their version:
1. They hooked it up to Apples native modal UI library so the AI could display what it was doing at each step in the top right of the screen. 2.
2. They used OCR to do precise clicking
Computer-operating agents continued to gain more traction over the year. More labs, more papers, and more teams focused on this type of framework. Namely, letting a VLM control a computer with a mouse and a keyboard, like a human does. Most notably, Anthropic recently unveiled their agent, called Computer Use:
"We’re also introducing a groundbreaking new capability in public beta: computer use. Available today on the API, developers can direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text."
Just today, on January 23, 2025, OpenAI announced Operator, "a research preview of an agent that can use its own browser to perform tasks for you. Using its own browser, it can look at a webpage and interact with it by typing, clicking, and scrolling."
I'm excited to see what the future holds. In the next five years, I expect advanced multimodal models to fully operate computers and handle long, complex tasks.
About The Name
It is worth mentioning that my original vision of a Self-Operating Computer powered by running Llava-1.5 locally eventually evolved into a project that gained popularity for using an external AI to operate the computer. The open-source community did eventually integrate Llava.
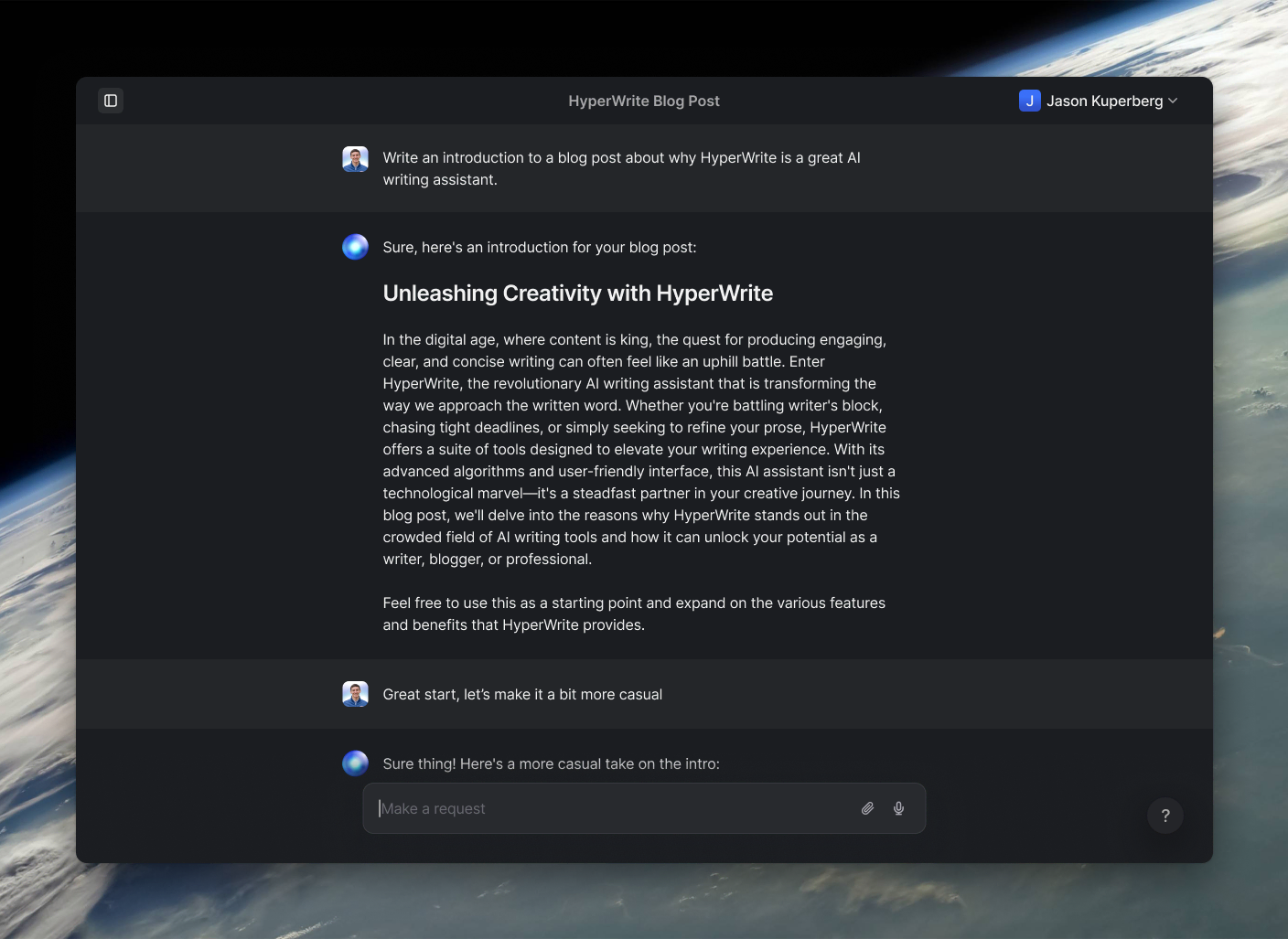
HyperWrite is the AI writing assistant that learns your style. It handles drafting, editing, and researching so you can focus on ideas.
- Autocompletes sentences as you type
- Works inside Google Docs & Gmail
- Adapts to your personal writing style
- 500+ AI tools for any writing task
Powerful writing in seconds
Improve your existing writing or create high-quality content in seconds. From catchy headlines to persuasive emails, our tools are tailored to your unique needs.